

Trying to predict the stock market has provided a fascinating prospect for data scientists who are more interested in challenging issues than financial gain. Every day you can see the ups and downs of the stock market and think about whether there are patterns that people or models (machine learning) can learn and based on what they have learned to overcome traders with specialized business qualifications and predict. Pay the scholarship?
Labels: Order to build a Forex robot , Build a stock trading robot , Build a trading robot , Trader robot design , Free Forex Robot , Forex robot programming , Forex Expert Making Tutorial , Build a trading robot with Python , Download Forex Trading Robot , Buy Forex Trader Robot , Automated Forex Robot , Free stock trading robot , Learn how to build a Forex trading robot , Alpari trading robot , Forex robot for Android , MetaTrader robot design , MetaTrader robot programming , Forex robot design , Forex robot programming , Automated trading
“When I started using different models to predict time series, I had to focus on stock market data with simulated capital,” says William Koehrsen in his article entitled “Python Stock Exchange Forecasting.” Let me test. So, I came up with ideas, and to see them flush it out, it’s really fun.
In the process, however, I learned Python, Object Oriented Programming (OOP), Data Manipulation, Modeling, and Visualization. I also figured out why you should avoid (allocating time and) playing daily with stock market data even without losing a dollar (in a simulated environment) (I can only say that this game is very time consuming).
Stock and technical analysis, data mining, artificial intelligence, Python
The point I have to make is that (in my opinion) there are three solutions when we fail at work:
- We have succeeded in twisting the results as it seems.
- Hide the results so that no one is aware of our failure.
- Show all our results and methods to others (and of course ourselves), because it makes people aware of previously used and unsuccessful methods, and they can use this information in future efforts to solve the problem, in a way that Solve better.
While option three is the best choice at the individual and social levels, it takes a lot of courage to do so. When the model makes a significant profit, the intervals can be given to it selectively, or they can be discarded and it can be pretended that there is no time to build this model, which of course is a very naive solution. “Mankind succeeds by failing and learning from its failures.”

Stock and technical analysis, data mining, artificial intelligence, Python
Another noteworthy point, of course, is the Python code written for difficult tasks such as stock forecasting (and many other codes written for other complex issues) even if the final output of the model is far from what is expected. Again, they are not considered useless code. In this article, the capabilities of the “Stocker” or “Stock Explorer” tool developed by William Koherson to predict the stock market in the Python programming language are examined, along with how it is coded. The full code of this program in GitHub (+) Is available for all people who want to use it or participate in this project.
Stocker to predict the stock market
Stocker is a Python tool for stock market exploration written by William Koherson using the Python programming language. In order to run this program, after the required libraries are installed, you can start Jupyter Notebook in the same script folder of the program and import the Stocker class.
This class is currently available. An object of class Stocker is created by passing any valid value of the stock ticker to it.
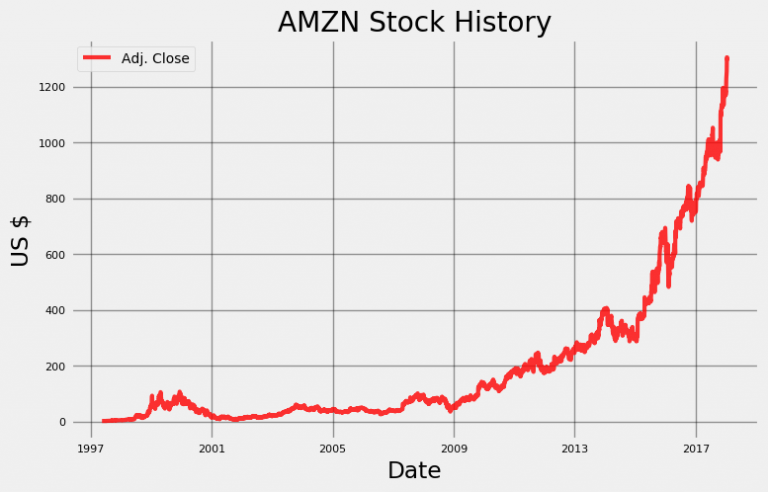
As can be seen from the output, Amazon stock data has been available for twenty years and can be explored. Stocker is based on the Quandl Financial Library with over 3,000 scholarships to use. Next, a simple diagram of the stock data history can be drawn using the plot_stock method.
Stock and technical analysis, data mining, artificial intelligence, Python
Stocker analysis capabilities can be used to find general trends and patterns in the data, but the focus is on how to forecast future stock prices based on past stock market data (time series). Stocker forecasting in Stocker using “Additive Model” (AM) which includes time series as a combination of a general trend with chapters at different time scales such as daily, weekly and monthly. Stocker also uses the prophet package created by Facebook for cumulative modeling. Building a model and doing stock trading in Stocker can only be done using one line of code.

Stock and technical analysis, data mining, artificial intelligence, Python
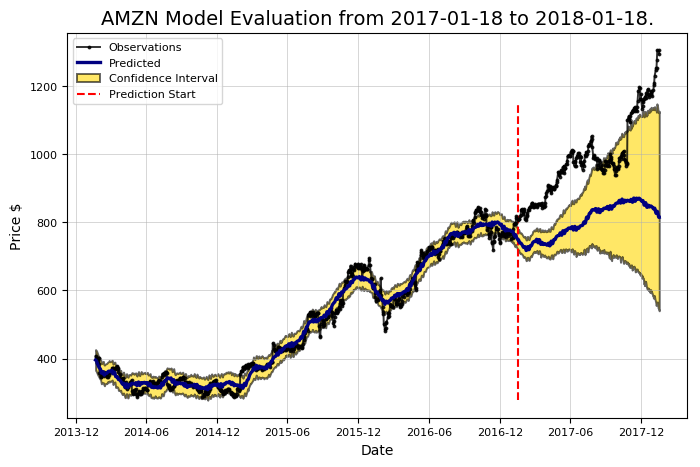
The forecast – the green line – contains the “Confidence Interval”. This indicates the “Uncertainty” of the model in the predictions. In this example, the confidence interval width is set to 80%, which means that this interval is expected to include the actual value in 80% of cases. The confidence interval widens over time as the estimate becomes more uncertain as the data moves further away. Whenever the stock market is forecast, confidence intervals must be taken into account. Although most people are looking for a simple answer about the future, predictions suggest that humans live in an uncertain world.
Anyone can predict the stock market by simply choosing a number, and the result is a prediction based on individual choice (William Koherson: “I may be wrong, but this is the way everyone on Wall Street is). have”). In order to be able to trust the model, it is necessary to evaluate its accuracy. There are also a number of methods in Stocker to evaluate the accuracy of the model.
Evaluate forecasts
Test and training data sets are required to calculate accuracy. The data miner needs to know the answers to the test set – the current stock price – so historical data from the past year is used to do this (in the example ahead 2017). During training, the model is not allowed to see the test data set responses, so data from three years earlier is used to assess the time frame (2014 to 2016). The basic idea of ”supervised learning” is that the model learns patterns and relationships between data from the data set and is then able to reproduce them correctly for test data.
At the same time, accuracy (quantitatively) is needed, so predictions are used for the test data set and current values. And the percentage when the actual price is within the 80% confidence interval. All these calculations are done by Stocker with good visualization.
Stock and technical analysis, data mining, artificial intelligence, Python
These statistics are non-scrollable! Just like a tap or a line. If one wants to use these statistics for investment, it may be better to do something more meaningful, such as buying a lottery ticket. However, work with this model is not over yet. The model is usually expected to perform poorly at first because it uses the default settings (hyperparameters).
If the initial attempts were not successful, these parameters can be changed for better results. There are various settings for setting up the Prophet model, the most important of which is the initial “changepoint” scale, which controls the amount of weight that the model places on changes in data orientations.
Select the change point priority
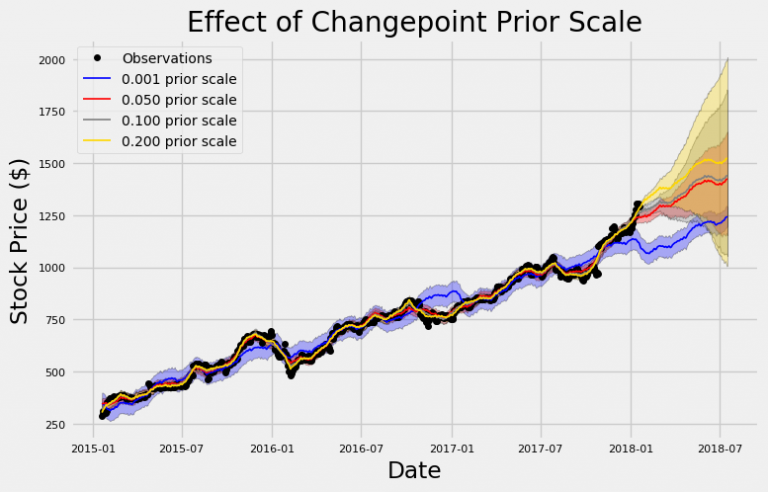
Points of change indicate neighborhoods where the time series has gone from declining or slow to rapid (or vice versa). These occur in areas with the largest changes in time series rates. The change point priority scale shows the amount of emphasis on change points in the model. This case is used to control “overfitting” and “underfitting”.
Higher priorities create heavier models at shift points and more flexible fit. This may lead to overfitting, as the model adheres strongly to training data and is unable to generalize to new test data. Reducing priority reduces the flexibility of the model, which can lead to the opposite problem, which is low fit.
This happens when the training data model does not follow closely enough and fails to learn the basic patterns. Understanding the right settings for the right balance is more of an engineering issue than a theoretical one, and here the experimental results must be trusted. The Stocker class includes two different ways to choose the right priority, visual and quantitative. In the following, the graphic (visual) method is used first.
Stock and technical analysis, data mining, artificial intelligence, Python
In this step, model training is done with three-year data and then forecasts are displayed for three months. Predictions are not quantified here because the only attempt is to understand the priority role of the change point. This diagram works extremely well in displaying over-over and under-over. Low priority – blue line – does not follow training data.
The black observations closely follow the training data and seem to do their job and choose a path from the public vicinity. However, the highest priority, the yellow line, is as close as possible to training observations. The default value for the change point priority is 0.05, which is somewhere between two of the extraordinary values.
Also, the difference between uncertainties (shared distances) is significant for priorities. The lowest priority has the highest uncertainty in training data, but has the lowest uncertainty on test data. The higher the priority, the greater the confidence in the training data, because it closely follows each observation.
However, when discussing test data, a hyperbola model is lost without any relevant data points. Because the stock market has little variability, the researcher may be looking for a more flexible model than the default model, so the model can record as many possible patterns as possible. Now that a clear idea of the impact of priority has been formed, it is possible to numerically evaluate different values using training and validation datasets.
Care must now be taken that the validation data does not resemble the test data. If this happens, it would seem that the best model for the data was built, but in fact the overdraft of the test data occurred and the model could not be used for real-world data. In general, as is commonly done in data science, three different datasets will be used: the education dataset (2013-2015), the assessment dataset (2016), and the test dataset (2017). .
Four priority measures were evaluated: training errors, training intervals (confidence intervals), test errors and test intervals (confidence intervals), and in all these measures all values are in dollars. As can be seen in the graph, the higher the priority, the lower the training error and uncertainty on the training data. It can also be seen that there is a higher priority for reducing test error, and it is a testament to the intuition that closely fitted data is more appropriate for stocks.
In the exchange for higher accuracy, a greater range of uncertainty is received on the test data with increased priority. Stocker’s previous assessment also shows two graphs that illustrate the following points.
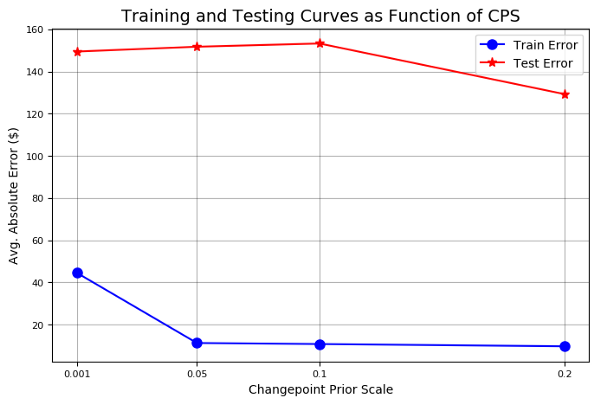
Stock and technical analysis, data mining, artificial intelligence, Python
Labels: Order to build a Forex robot And Build a stock trading robot And Build a trading robot And Trader robot design And Free Forex Robot And Forex robot programming And Forex Expert Making Tutorial And Build a trading robot with Python And Download Forex Trading Robot And Buy Forex Trader Robot And Automated Forex Robot And Free stock trading robot And Learn how to build a Forex trading robot And Alpari trading robot And Forex robot for Android And MetaTrader robot design And MetaTrader robot programming And Forex robot design And Forex robot programming And Automated trading
Because the highest priority results in the lowest test result, one should try to increase the priority to see if this results in better performance. Search results can be refined by passing added values to the evaluation method.
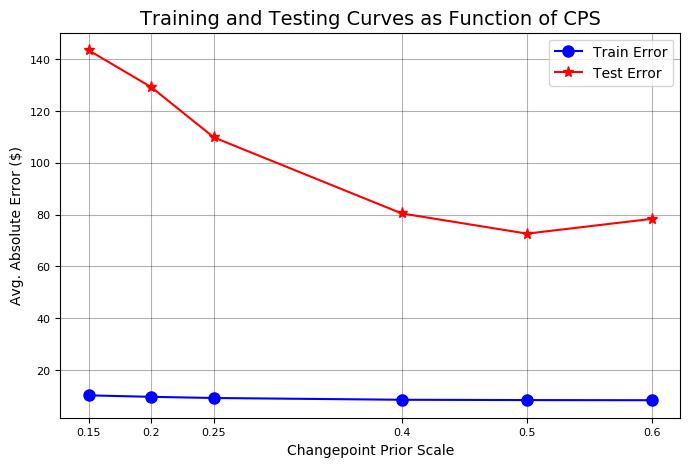
Stock and technical analysis, data mining, artificial intelligence, Python
Test set error is minimized at priority 0.5. The change point priority property for the Stocker object is set appropriately.
There are other settings for the model that the user can configure, such as the patterns that are expected to be seen or the number of years of test data that the model uses. Finding the best combination requires repeating the above procedure with different values. The audience of this article is advised to repeat the procedure stated above with different values.
Evaluate the refined model
Now that the model is optimized, it can be re-evaluated.
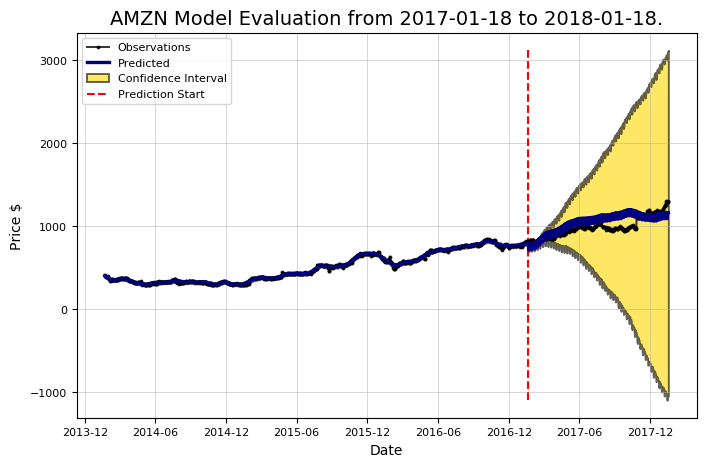
Stock and technical analysis, data mining, artificial intelligence, Python
It looks better. This indicates the importance of model optimization. Using the default values provides a fair initial guess, but you need to make sure that the correct model settings are used, as a stereo sound is optimized by adjusting various items.
Play with the stock market
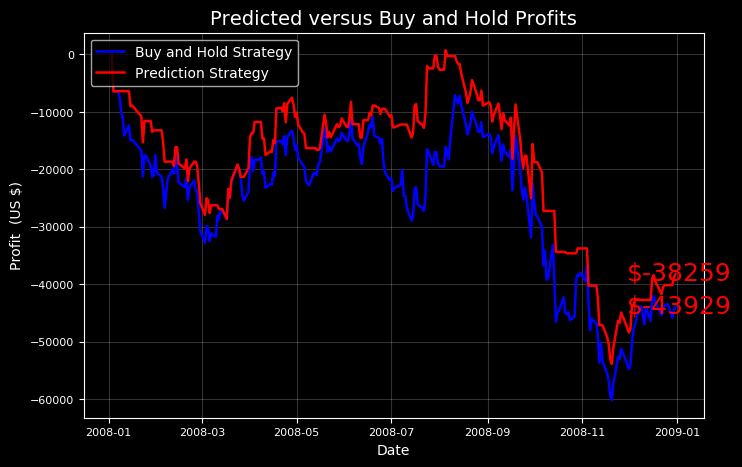
Making stock predictions is an interesting exercise, but the real fascination is looking at how these forecasts work in the real market. Using the evaluate_prediction method, you can play with the stock market using the existing model during the evaluation period. In the following, the strategy whose information is obtained from the existing model will be used. This strategy is comparable to the simple stock buying and holding strategy throughout the period.
The rules of this strategy are clear and as follows:
- For each day that the stock forecast model predicts, stocks can be bought at the beginning of the day and sold at the end of the day. No stock should be bought when the model predicts that stock prices will fall.
- If a stock is bought by an individual and its price increases during the day, there will be an increase in the number of shares purchased.
- If the stock is bought by a person and its price decreases, money is lost as the number of shares decreases.
This game must be played every day throughout the evaluation period. In this example, the period is equal to 2017. To play the game, the number of shares is given to the method call. Stocker informs the user of the outcome of his strategy with numbers and charts.
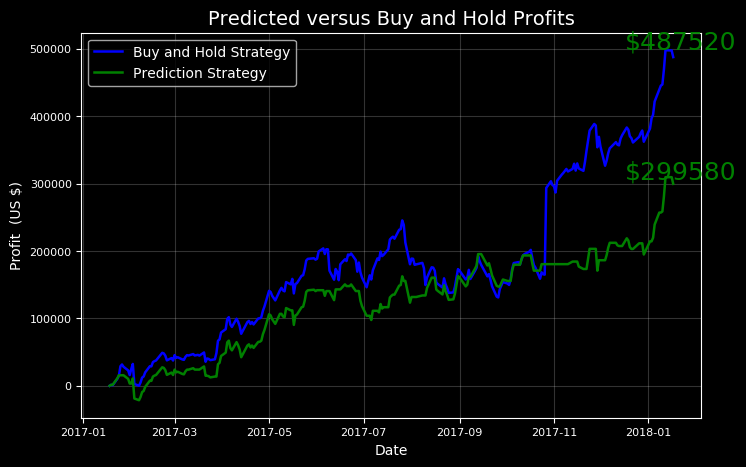
Stock and technical analysis, data mining, artificial intelligence, Python
This output has a remarkable lesson: Buy and hold! While a significant amount of achievement could have been achieved with the previous strategy, the best solution is to invest for a long time. You can try another test period to see if there are times when the existing model strategy overcomes the buy and hold method.
The existing strategy is conservative because the user does not enter the game when he knows the market is shrinking, so it is expected to perform better when the market shrinks than when the buy and hold strategy is used.
Stock and technical analysis, data mining, artificial intelligence, Python
Always use unrealistic money to evaluate your model and predictions!
Predicting the future
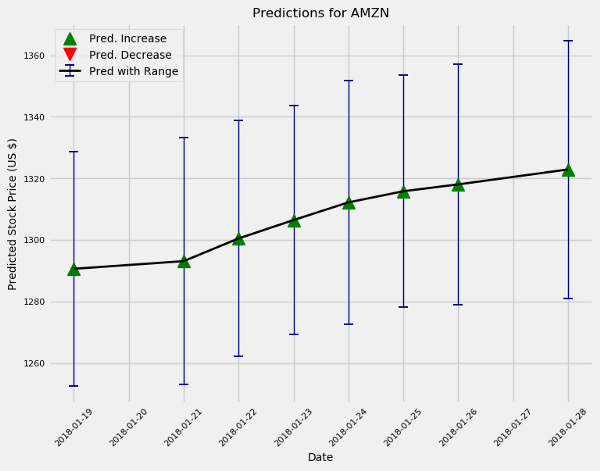
Now that the existing model is found to be good enough, we can predict the future using the predict_future () method.
Stock and technical analysis, data mining, artificial intelligence, Python
Stock forecast for the next 10 and 100 days
This model is often bullish for Amazon stocks because it features the most professionals. In addition, uncertainty increases over time (which the user estimates as expected). In fact, if this model is used for active trading, a new model is taught every day and in the future can predict the stock market for a maximum of one day.
Although one may not get rich with the Stocker tool, the real benefit is in building and developing the model, not the end result. Until the model is actually tested, it is not possible to know if it has been able to solve a problem, but trying and failing is better than doing nothing. People who are interested in developing this model or building their own model based on it can download the Stocker code in the project gateway (+) Review.
Labels: Order to build a Forex robot , Build a stock trading robot , Build a trading robot , Trader robot design , Free Forex Robot , Forex robot programming , Forex Expert Making Tutorial , Build a trading robot with Python , Download Forex Trading Robot , Buy Forex Trader Robot , Automated Forex Robot , Free stock trading robot , Learn how to build a Forex trading robot , Alpari trading robot , Forex robot for Android , MetaTrader robot design , MetaTrader robot programming , Forex robot design , Forex robot programming , Automated trading






